Dieser Beitrag ist im Tagungsband "Fortschritte der Akustik -
DAGA '96" veröffentlicht.
Objektive Sprachqualitätsvorhersage mittels
einer gehörorientierten Vorverarbeitung
Martin Hansen, Torsten Dau, Birger Kollmeier
AG Medizinische Physik, Fachbereich Physik, Carl von Ossietzky-Universität
Oldenburg
Einleitung
Bei der objektiven Sprachqualitätsvorhersage ist man daran
interessiert, subjektive Qualitätsverschlechterungen eines
verzerrten Test-Sprachsignals gegenüber dem ungestörten
Referenzsignal mit Hilfe physikalischer Parameter zu quantifizieren.
Dabei ist man dazu übergegangen, eine möglichste
gehörgerechte Vorverarbeitung der Sprachsignale zu
berücksichtigen, da traditionelle Signalparameter wie der
Signal-Rauschabstand bei nichtlinearen Sprach-Codier-Decodier Systemen
Codecs versagen, /1/-/5/.
In diesem Beitrag wird ein Verfahren zur objektiven
Sprachqualitäts-Vorhersage von niederratig codierten
Sprachsignalen vorgestellt, das auf einem Modell zur
gehörgerechten Signalverarbeitung basiert. In vorangegangenen
Untersuchungen /6/ konnte gezeigt werden, daß dieses Modell die
Wahrnehmungsleistung des menschlichen Gehörs in einer Vielzahl
von psychoakustischen Experimenten ergfolgreich beschreiben kann.
Methode der Sprachqualitätsmessung
Zuerst wird die Zeitverzögerung zwischen Referenzsatz und
verzerrtem Satz ausgeglichen und beide Sätze global auf gleichen
rms-Wert skaliert. Beide Sätze werden dann mittels einer
gehörgerechten Vorverarbeitung auf die Ebene ihrer sogenannten
"internen Repräsentation" abgebildet. Unterschiede
zwischen den internen Repräsentationen von Referenz- und
verzerrtem Satz sollten wahrnehmbaren Unterschieden in den
Zeitsignalen entsprechen und damit eine verringerte
Sprachqualität bedeuten.
 Die implementierte Signalvorverarbeitung zur
Berechnung der internen Repräsentation ist in Abbildung 1
dargestellt.
Die implementierte Signalvorverarbeitung zur
Berechnung der internen Repräsentation ist in Abbildung 1
dargestellt.
Die Signalvorverarbeitung besteht aus einer
Filterbank, die das Signal in frequenzgruppenbreiten Bändern mit
Mittenfrequenzen von 300 bis 4000 Hz bandpaßfiltert, gefolgt von
einer Halbwellengleichrichtung und Tiefpaßfilterung, die das
Übertragungsverhalten der Haarzellen angenähert nachbildet.
Zur Modellierung zeitlicher Verdeckungseffekte und adaptiver
Kompression schließt sich eine Kette von Nachregelschleifen /7/
an. Diese bestehen aus fünf hintereinandergeschalteten
Dividierern, deren Divisor jeweils ihr tiefpaßgefiltertes
Ausgangssignal ist. Die Nachregelschleifen haben die Eigenschaft,
stationäre Eingangssignale auf die 32. Wurzel, y =
x^(1/32) ~= log(x), in ihrer Amplitude zu komprimieren.
Schnelle Schwankungen der Einhüllenden am Eingang werden dagegen
nahezu linear übertragen, da die Divisoren sich nur
gemäß der Zeitkonstanten der Tiefpässe ändern
können. Die fünf Zeitkonstanten sind linear aufsteigend
zwischen 5 ms und 500 ms verteilt. Am Ende der Nachregelschleifen
begrenzt ein einfacher Tiefpaß 1. Ordnung mit einer
Zeitkonstante von 20 ms das Auflösungsvermögen für
zeitliche Einhüllendenfluktuationen.
Die einzelnen Frequenzbänder werden gewichtet. Als
Wichtungsfunktion wurde die 40-Phon Isophone gemäß ISO 226
im Bereich von 300 bis 4000 Hz verwendet. Als Maß Q
für die Unterschiede zwischen den beiden Repräsentationen
wird der Korrelationskoeffizient zwischen den entsprechenden Samplen
berechnet. Der maximale Wert von 1 entspricht also einem
transparenten Codec. Das so definierte Qualitätsmaß
Q kann durch eine monotone Funktion auf die subjektive Mean
Opinion Score-Skala (MOS) abgebildet werden.
Ergebnisse
Die beschriebene Methode wurde auf das Material des ETSI Halfrate
Selection Test (1992) angewendet. Er enthält jeweils vier
unterschiedliche Doppelsätze inklusive Pausen, von zwei weiblichen und
zwei männlichen Personen gesprochen. Die Sätze wurden durch 6
verschiedene Codecs bei jeweils 6 verschiedenen Arbeitsbedingungen
verzerrt. Zu diesen 144 Sätzen kommen als Referenz 36 weitere hinzu,
die durch einen MNRU (Modulated Noise Reference Unit) mit verschiedenen
S/N-Werten verzerrt wurden.
Um Schwankungen der subjektiven Sprachqualität auszugleichen, die
auf der Variabilität der verschiedenen Sprechstimmen beruhen,
wurden die jeweils vier Sätze einer Codec-Bedingung zu einem
langen Satz hintereinandergehängt und der mittlere MOS berechnet.
In Abbildung 2 sind die Ergebnisse der
Sprachqualitätsvorhersage dargestellt. Die subjektiv gemessene
Sprachqualität (MOS) ist als Funktion des objektiven Maßes
Q aufgetragen. Jeder Datenpunkt ist mit der Nummer des Codecs
(1-6) innerhalb des Tests bzw. durch ein m
für den MNRU markiert.
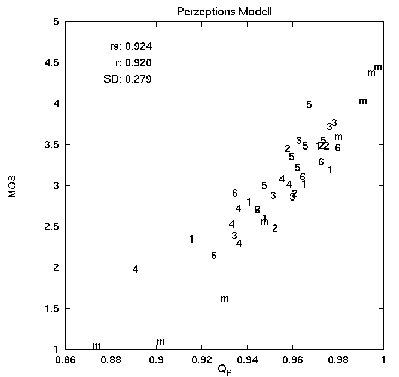 Aus Abbildung 2 erkennt man eine hohe Korrelation der Q/MOS
Datenpunkte und eine geringe Schwankungsbreite, innerhalb der die
subjektiven MOS-Werte bei festem Q variieren. Der
Rang-Korrelationskoeffizient beträgt 0,924, die
Standardabweichung für ein angepaßtes Polynom 2. Grades
beträgt 0.279. Der Korrelationskoeffizient ist damit sehr hoch
und vergleichbar mit dem Wert, den z.B. Beerends gibt für sein
Sprachqualitätsmaß PQSM /2/ für den
niederländisch-sprachigen Teil desselben Tests angibt (0,94).
Obwohl die Codecs und besonders der MNRU jeweils sehr unterschiedliche
Verzerrungen erzeugen und verschiedene subjektive Klangeindrücke
mit sich bringen, läßt sich in Abbildung 2 keine
Gruppierung der Datenpunkte für einzelne Codecs erkennen. Dies
deutet darauf hin, daß die verwendete Vorverarbeitung, in
Kombination mit dem Korrelationskoeffizienten als
Qualitätsmaß, für verschiedene Arten von Verzerrungen
eine "perzeptiv richtige" Sprachsignalanalyse leistet. Diese
Annahme wird durch Untersuchungen von Tchorz et al. /8/
bestätigt, der dieselbe Vorverarbeitung zur Merkmalsextraktion
für Spracherkennungsalgorithmen verwendet.
Aus Abbildung 2 erkennt man eine hohe Korrelation der Q/MOS
Datenpunkte und eine geringe Schwankungsbreite, innerhalb der die
subjektiven MOS-Werte bei festem Q variieren. Der
Rang-Korrelationskoeffizient beträgt 0,924, die
Standardabweichung für ein angepaßtes Polynom 2. Grades
beträgt 0.279. Der Korrelationskoeffizient ist damit sehr hoch
und vergleichbar mit dem Wert, den z.B. Beerends gibt für sein
Sprachqualitätsmaß PQSM /2/ für den
niederländisch-sprachigen Teil desselben Tests angibt (0,94).
Obwohl die Codecs und besonders der MNRU jeweils sehr unterschiedliche
Verzerrungen erzeugen und verschiedene subjektive Klangeindrücke
mit sich bringen, läßt sich in Abbildung 2 keine
Gruppierung der Datenpunkte für einzelne Codecs erkennen. Dies
deutet darauf hin, daß die verwendete Vorverarbeitung, in
Kombination mit dem Korrelationskoeffizienten als
Qualitätsmaß, für verschiedene Arten von Verzerrungen
eine "perzeptiv richtige" Sprachsignalanalyse leistet. Diese
Annahme wird durch Untersuchungen von Tchorz et al. /8/
bestätigt, der dieselbe Vorverarbeitung zur Merkmalsextraktion
für Spracherkennungsalgorithmen verwendet.
Literatur
/1/ M. Hansen und B. Kollmeier. "Anwendbarkeit eines psychoakustisch
motivierten Sprachvorverarbeitungsmodells für die
Sprachqualitätsmodellierung". In Elektronische
Sprachsignalverarbeitung, 34-39. ITA Dresden, 1995.
/2/ J. G. Beerends und J. A. Stemerdink. "A Perceptual Speech
Quality Measure based on a Psychoacoustic Sound Perception". J. Audio Eng. Soc., 42 (3):115-123, 1994.
/3/ J. Berger und A. Merkel. "Psychoakustisch motivierte
Einzelmaße als Ansatz zur objektiven Qualitätsbestimmung
von ausgewählten Sprachcodiersystemen". In Elektronische
Sprachsignalverarbeitung, TU-Berlin, 1994.
/4/ M.R. Schroeder, B.S. Atal, und J.L. Hall. "Objective Measure of
Certain Speech Signal Degradations Based on Masking Properties of
Human Auditory Perception". In Frontiers of Speech
Communication Research, 217-229, London, 1979. Academic Press.
/5/ S. Wang, A. Sekey und A. Gersho. "Auditory Distortion Measure for
Speech Coding", In IEEE Proc. Int. Conf. Acoust., Speech Signal
Processing, 493-496, 1991.
/6/ T. Dau und D. Püschel. "Ein Computermodell zur Verarbeitung
komplexer Schallreize". DAGA '92, 877-880.
/7/ D. Püschel "Prinzipien der zeitlichen Analyse beim
Hören". Dissertation, Uni Göttingen, 1988.
/8/ J. Tchorz, M. Wesselkamp und B. Kollmeier. "Gehörgerechte
Merkmalsextraktion zur robusten Spracherkennung in Störgeräuschen",
dieser DAGA-Band.
Diese Arbeit wurde vom Forschungszentrum der Deutschen Telekom AG
unterstützt.
Back to speech quality home page
martin@medi.physik.uni-oldenburg.de
Last modified:
Fri Aug 2 11:31:38 1996